The 2010s and alternative Social Media: A decade full of work, hope, and disappointment
Regardless of whether you think that the next decade started just now or goes on for another year1, you have to agree that having the least significant digit roll over just looks nice. Since this year-increment seems like a reset of a counter of some sort, I will gladly take this opportunity to ramble a bit on the last ten years of working on free and open-source, alternative, federated social networks - and on the internet in general. This is very ramble-y. You have been warned.
A quiet decade for the internet
It has been a quiet decade for centralized networks. To see how quiet exactly, let us look at Facebook together. In 2011, they removed the ability to write on people’s walls, and instead ordered posts in a hot and new, always-chronological timeline. Facebook figured out people are tired of sending messages in a cumbersome UI, so they launched the “Messenger” app as a standalone “instant” messaging tool. In 2012, they acquired Instagram for roughly half my monthly salary, or $1 billion if you do not know my earnings. The same year, Facebook welcomed its first one billion users. In 2013, they made their “Graph Search” available to all, allowing everyone to stalk their friends and coworkers with even greater detail. In 2014, Facebook ate WhatsApp for breakfast after exchanging $14 billion. While they went on eating other companies, they spent another $2 billion on Oculus. In 2017, they crossed the 2 billion Monthly Active Users mark. In 2018, they launched an internet-connected surveillance camera attached to a voice assistant. While some people raised their eyebrows at potential privacy implications, Cambridge Analytica accidentally collected very private data from 87-something million Facebook users. It later turned out that these profiles were used to interfere with some US and UK elections. The US Senate was not too pleased, so they invited Mark Zuckerberg over for dinner. In 2019, Facebook got caught paying children a couple of bucks to install an app to their phone that allows Facebook to collect even more, and even more private data about them. Quiet, I tell you, quiet.
Okay, I will stop with the overly passive-aggressive sarcasm now. The 2010s have been a huge decade for the internet, and a harrowing one as well. Almost every larger network has had issues of some sort, either security-related or simply because of their lack of interest in privacy. More and more people live most of their lives online, and more and more critical systems are now on the internet. I am not only talking about social media, though. We have observed companies like Equifax with massive security breaches, exposing personal data from millions of users.
I seriously do not expect this to get better next decade. If anything, these issues will get drastically more severe. The more people and companies store their data online, the more attractive those systems are to attackers of any kind. Users and politicians appear to have finally understood this reality, but it still feels like most are mainly interested in damage control, as opposed to finding actual solutions.
But do people really care about privacy?
We have all heard politicians advocating for more privacy and new regulations to enforce privacy. Some countries or states have put stricter data protection rules into their legislatures, and while the actual effectiveness of those can be questionable, the symbolic act itself is exciting. Internet users are very vocal about the concerns they have and claim companies like Facebook and Google need to do more to protect their user’s data.
However, while it is refreshing to see some outrage by users, I have to question the substance behind that. Most people do not realize that the exact things they are complaining about are what makes those services work as they do, and these things are what makes running those services financially viable in the first place. Yes, Facebook does collect tons of personal information and shows your friend’s posts only if they pass opaque filters in some proprietary algorithms, but that is the reason why you do not get flooded with tons of posts you do not care about. Yes, Google does collect a lot about you, but that is the kind of information they use to show you search results you care about2, and that is the data they use to show you advertisements that hopefully turn you into a bit of profit.
You cannot complain about Facebook collecting your life’s history, while at the same time complaining that diaspora* cannot find your former classmates. You cannot complain about WhatsApp collecting your address book, while at the same time stating you do not use eMail because exchanging addresses is too cumbersome. You either get a system that knows who you are or a system that does not. I do not get the impression that the majority of users who complain about “bad privacy practices” have understood that point yet.
How are alternative projects doing?
With so much outrage about the centralized commercial systems, one would expect alternative projects to do quite well. But do they? Here is a graph3 showing Monthly Active Users in some projects working on alternative, federated social media:
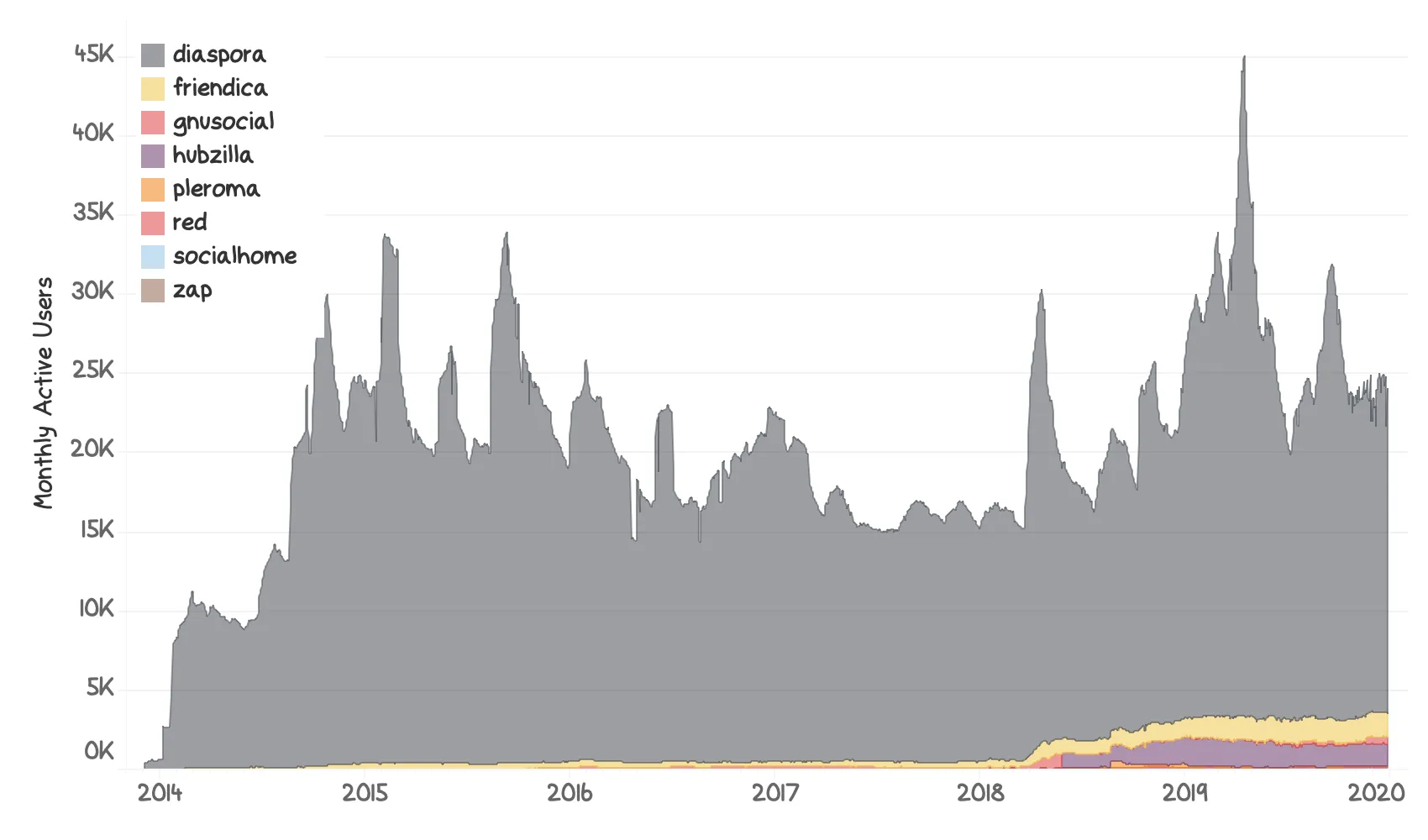
So, uh. If we are precise, we can see that all projects grew a bit since 2018, when the first wave of scandals popped up. However, the amount of growth is negligible compared to the billions of users Facebook and Friends are handling every day. Diaspora*, in particular, shows a huge spike every time a new collection of privacy issues surface the world, but the users do not stay for very long. Most of them just show up, explain how they will not use Facebook ever again, only to end up back there in a month or two. This is a pattern we have seen for quite a while.
Careful viewers might realize that the chart above is missing one big player in the field: Mastodon. And yeah, that is true, I left it out deliberately. Here is the same graph, but with Mastodon added.
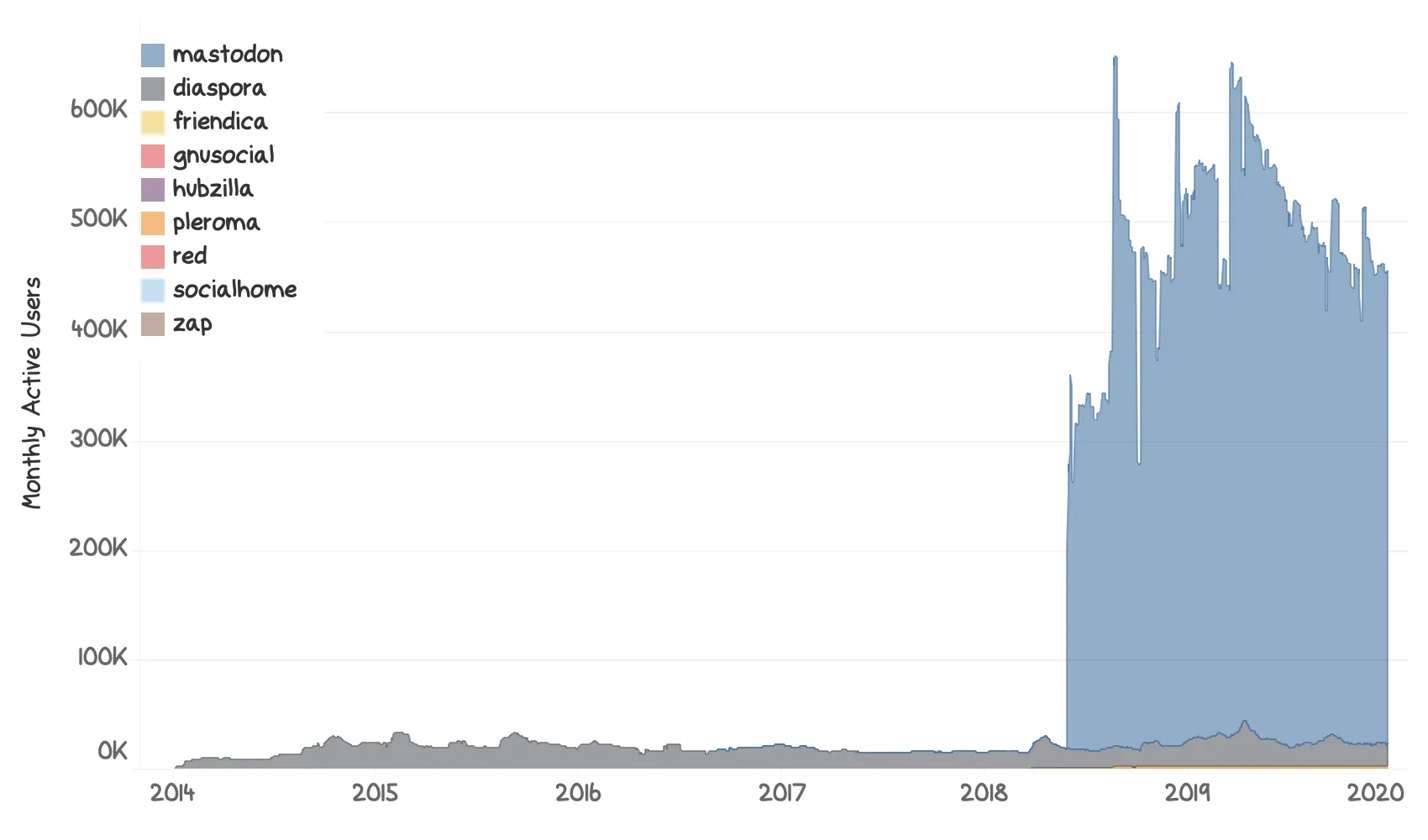
I think everyone will agree that the chart is a bit less usable4 now. Mastodon is big enough to completely mess up the scaling for all other networks, to a point where diaspora* is the only thing easily observable. Now, yes, I could have switched to a logarithmic scaling, but then, the chart would not tell the story about how big Mastodon actually is. And that is an interesting piece.
Mastodon did a lot of things right in the beginning. Their interface looks a bit like Tweetdeck and Hootsuite, so everyone familiar with those tools felt right at home. They hit the perfect timing and launched just as a new privacy scandal was exposed, so it was easy for journalists to show off the new kid on the block. And, probably the most essential piece: They had tools available to cross-post from Twitter to Mastodon, basically on day zero. At first, this sounds like a minor thing, but a lot of people signed up on Mastodon and cross-posted their tweets to Mastodon. This means that there was a lot of content available on Mastodon from the beginning, and the users never stopped pouring material into Mastodon, even if they left and went back to using Twitter exclusively. Today, there still is a lot of traffic just from cross-posting tweets.
One popular tool used for cross-posting provides us with public statistics, and we can see that in the course over the last four weeks as of writing this post, 700k tweets have been processed by this tool alone. That is a lot of content, and a lot of apparently active users on Mastodon. Back when the official Mastodon relay was still a thing, I once recorded a month’s public toots and ran some numbers on them. More than two-thirds of all posts received were just straight up automated posts sharing people’s tweets. Besides, I could observe a lot of bot activity from people writing bots to share RSS feeds and whatnot on Mastodon. This tells us that there is a high chance that a significant portion of Mastodons Monthly Active users are not users, but bots, cross-posting content from other sources. However, it could be that all those users are real - we simply do not know, and there is no way for me actually to check that. In any case, this vast amount of content and apparent activity makes Mastodon more attractive on a first glance. Still, even Mastodon’s Monthly Active User numbers are taking a massive hit these days. While I do not have enough information to speculate about why that might be, it is interesting, nonetheless.
One might ask why user retention on those projects is so small, and why adoption, in general, is not high. To a point, I already answered this by explaining the conflict of user interests earlier. No federated social network is, at this time, even close to being as comfortable and as rich as their centralized counterparts. There simply are no easily accessible alternatives for those users, even if they are deeply frustrated with what they are using right now.
Technically united
It feels like large portions of the “Federated Social Network” space, for the lack of a better term, are way too tech-focused, and completely lost track of what they once were claiming to do. We tend to be laser-focused on coming up with new technical challenges to solve, new bugs to fix, and new features to implement. But does it matter? What use is a social network with all the features imaginable, but no users to use them? What use is a perfectly abstracted and well-designed federation implementation, when there is no data to federate?
I wish that more people would consider the reason behind billions of users still using Facebook, instead of just going along their lives as a coder working on whatever their favorite project is. It is disappointing to see so many active people in this field to just say, “oh well, they simply did not learn from their mistakes”, and go on as if that was no big deal. In reality, most people are very unhappy with the current situation, and they would probably love to use alternatives that respect their privacy more. Still, they just cannot consider projects like Mastodon or diaspora* proper alternatives - for a good reason.
Thinking outside of your little technical bubble is hard and uncomfortable. Sometimes, it takes a lot of time and effort, and sometimes, you have to make decisions that violate your principles for the sake of actually helping people. I have seen too many individuals, projects, and organizations get busy petting themselves on their backs for fixing a bug nobody cares about, or for hosting a service nobody cares about, or for writing marketing material nobody reads. I have seen way too many instances of organizations being stuck in their ideology, to a point where they entirely stop fulfilling their original purpose: to bring people forward.
It feels a lot like the reason we are unable to offer real alternative social networks is not that we cannot do so. It is because most people with the abilities to do so spend their time working on things that only work for the tiny audience that is the tech sector, while happily ignoring the needs of all those billions of non-technical humans out there. This is something that frustrates me more than I want to admit.
Dealing with criticism
One very interesting and somewhat surprising lesson of this decade was about the way some groups deal with criticism. Especially in the field of alternative social media, I get the impression that most people think very binary there: either you fully support them, so you are their friend, or you do not fully support them, which turns you into their public enemy number one.
In early 2018, I published an article about ActivityPub, followed by a follow-up in 2019. In case you did not get the chance to look into these posts, there is no need to do so right now. These two posts outline my issues with ActivityPub, mainly that the specification is designed in a way that offers no guarantees whatsoever for any kind of interoperability, and the articles explained why I think this is a huge mistake. I expected to receive some negative feedback about those articles, mainly from people who spent a lot of time working on writing the specifications, and I expected general support for my points from people who work on implementations.
What I got was the exact opposite, and in a way that I found quite shocking, to be completely honest. Several folks who worked on ActivityPub, ActivityStreams, and other more or less related specifications reached out to me and told me they agree with pretty much everything I wrote. In general, people familiar with specifications and interoperability agreed that ActivityPub is less a specification for an actual protocol, but more a framework, which opens options for further dialects to be worked out, and specified on their own. Some implementors agreed with this statement, saying it is quite painful to implement these specs because there is no “source of truth” to work from. However, several other implementors decided this was an excellent opportunity to call my arguments “personal”, “biased”, and some argued that I just wrote what I did because diaspora* was just too lazy to refactor some code.
The tamest reaction out of all was an article published by an organization that claims to “spread knowledge about federated web projects and help people and projects involved in this area”, where one implementor took the time to take all my points and explain how you can work around those. The overall resentment of this reply was “you can implement ActivityPub just fine, you just have to talk to every single other implementation to make sure you are compatible”, which is exactly the point I criticized in the first place, so this “reply” actually does nothing. Many of my non-technical claims, for example, my argument about non-technical users being confused when multiple pieces of software all carry an “ActivityPub” label but then cannot talk to each other because of by-design incompatibilities, have been ignored entirely.
Writing this post and reading the responses just further confirmed what I was already thinking, and what I explained earlier: Non-technical people do not matter in those discussions. Possible confusion for people who do not understand the difference between “software”, “protocols”, “nodes”, and whatnot do not matter in this discussion. All that matters is that there now is a fancy hyped-up specification that everyone needs to support, and if a project decides not to support it, that project has to be the source of all evil.
I honestly stopped caring at this point. There still are people working on coming up with “one protocol to rule them all”, and I sincerely wish them good luck in the future, but I - like many others - do not think that this is ever going to happen.
However, compared to some people, I do not consider this a bad thing - quite the opposite. There always have been different tools for different purposes. There is a reason why people usually do not post their Tweets to Facebook, their birthday wishes from Facebook to Twitter, and there is a reason why people typically do not post links to their photos on Flickr to their Facebook timeline. Different applications fill different needs, and sometimes, forcing those various applications to be compatible with each other does not make much sense. I do not want to see microblog-like announcements every time someone uploads a photo to their photo-app, and I do not want my diaspora* stream filled with people microblogging their lives. I have different tools for that.
Sometimes, staying independent means staying in a place where you can iterate on new ideas. As long as we make sure we stay open, our documentation is always up-to-date, and we do not lock people in, I am more than fine working on a project that is not “compatible” with all the cool kids on the block. In a world where no alternative social network has any meaningful userbase whatsoever, there are more important things to care about. But apparently, my opinion is the minority in the full world of projects.
Looking ahead
Usually, these “looking back at the past” posts end with an optimistic outlook into the future. I tried hard to come up with ideas on how the future might look like, but I decided to give up. I have no idea.
I hope that we, as in “the entire internet”, eventually find our ways back into a place where we can argue with rational arguments instead of disliking someone’s opinion just because you so happen to dislike the person arguing. If we want to move forward, we have to be productive and constructive, not destructive. But who knows if and when that will happen.
As for social media in general, I think it is pretty evident that traditional social media is slowly dying. Facebook’s acquisition of WhatsApp was no mistake. More and more people dislike the self-presentational nature of classic social networks, and they move to more instant messaging-like applications like WhatsApp. Initially, I hated the idea, but today, I find myself chatting on services like Telegram, Signal, and even Discord, in more depth and more regularity than I ever managed my social media presence. I do not think this is an unfortunate trend overall; I think it is very healthy. Going back to having conversations, either with individuals or with a group of people inside group chats, is a way more sensible way to share private information, as compared to just posting them on a timeline on some social network. Users of chat applications have to actively decide with whom they want to share before sharing anything. Maybe this is an opportunity for us privacy-focused projects, and perhaps, services like WhatsApp is something we should focus on, instead of trying so hard to make federated classical social networking happen.
Maybe the solution is not to focus on applications that collect and analyze data, but instead working on the applications that store these snippets of information. Maybe, instead of building social networks, we should create a “control your own data”-like data storage service, which can be used by many applications. Maybe.
I… I really have no idea. This was supposed to be a post about the last decade, not the upcoming years. I still have not yet quite figured out what I should be working on in the long term, so I will just leave it here. Thank you for reading.
Footnotes
-
I am totally on team-2020 here. I like to start counting at zero, but a very non-representative study within my social circles did not come up with definite results. ↩
-
Yes, even at Google, your data is not exclusively used for advertisement. My favorite example here is the Google search for “Rust.” If Google considers you a software-person, you will see a lot about the programming language. Otherwise, it will show you results about oxidized metals. This is an extreme example, but there is a ton of little things like this. ↩
-
Huge data disclaimer here. The data source is a site collecting statistics from various projects and their instances, but the data is of questionable quality. Projects like diaspora* do not collect statistics per default, or may not have done so at the beginning of their lifetime. Submitting the statistics to one of the aggregators, like the site I got the data from, is entirely optional. Some projects report no data, or different kinds of statistics, so direct comparison is impossible. Given the opt-in nature of these statistics, we have no idea about how much of the network we actually cover. I guess that the absolute numbers are entirely unusable, but in regards to discovering trends, I think it works out good enough. ↩
-
Also, public statistics and their collection started late for Mastodon, so we do not have numbers on how things looked like in its early time. Mastodon-specific statistics existed previously, but all sites have been shut down in the meantime. ↩