Dynamic Denial of Crawlers
Okay, I’m not gonna lie, this isn’t quite what I expected my next blog post to be about - but I’m irritated, intrigued, and somewhat angry, so y’all get a rant.
A few months ago, I went mildly viral ranting about how LLM crawlers caused operational issues running some of the diaspora* infrastructure, and how 70% of the traffic I saw on those web properties was just serving LLM crawlers. It was on the front page of the Orange Site for a while1, and there were a few tech press articles about it2. It was fun all around. The best outcome, however, was that after I ranted, pretty much all crawling… stopped. I still don’t know why, but hey, I take it.
In recent days, I’ve seen something that’s somehow even more intriguing. Have a look at this traffic chart, which is from a different web thingie I run:
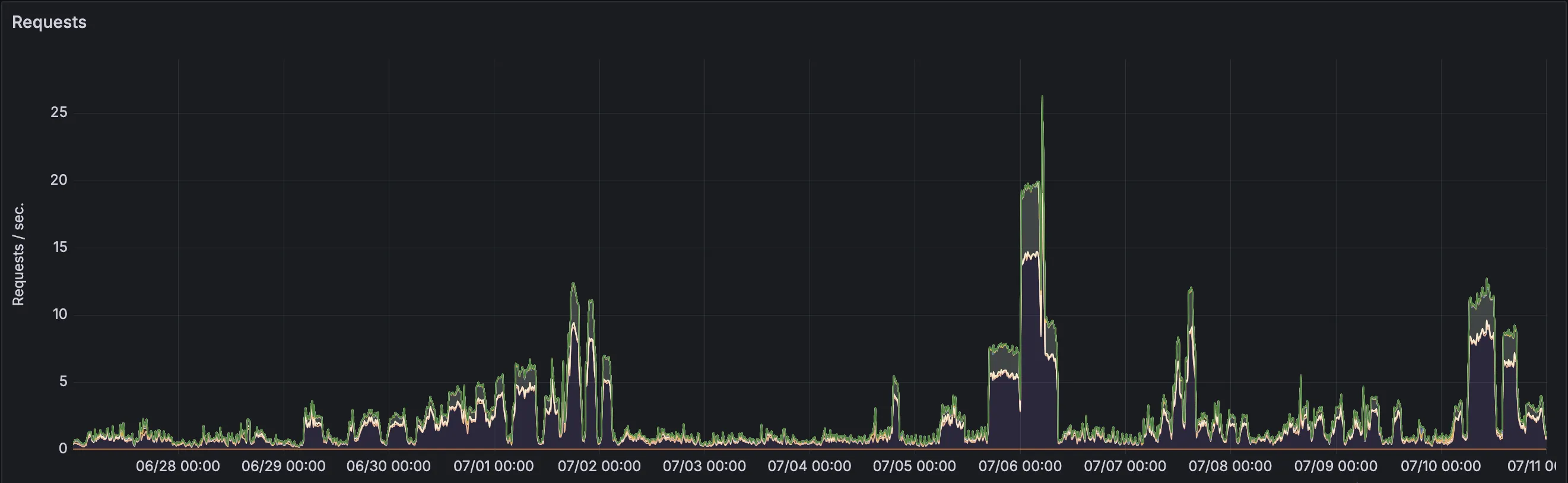
Isn’t that just beautifully bizarre? This is either the world’s worst DDoS attempt, or a very interesting crawling pattern - and I honestly can’t tell what it is. And the best thing is: a friend who runs a similar thing to the thing I run has exactly the same traffic patterns on their infrastructure at the same time!
If I only look at the areas of “higher than usual traffic”, I end up with 206 hours, totalling around 2.7 million requests. That averages out to 3.6’ish requests per second, but as you can see from the graph, there are these weird plateaus at 5, 10, and 15 req/s. This isn’t enough to bring down the application in question, but it is enough to severely annoy me.
During these high-activity periods, I can see a total of 1.3 million different client IPs - so each client did, on average, only slightly more than two requests. A lot of clients even just did a single request. The traffic logs I look at would include requests to assets like CSS or images. Those clients did not download any stylesheets or content images, so they’re clearly bots. But… why?
There is no clear pattern in the URLs either. The top URL is a login URL to which bots get redirected3 after clicking on something that would require them to be logged in. But everything else is just… random user-generated content URLs. I can also see from the network traffic analysis that the clients download and receive the full responses, so it’s unlikely to be DDoS traffic and just looks like a crawler botnet. But… why run a crawler from millions of IPs?
Looking at the User Agent header statistics reveals absolutely nothing. The top four ranks are:
- 467k requests from “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0”
- 275k requests from “Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Mobile Safari/537.36”
- 215k requests from “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36”
- 126k requests from “Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/20100101 Firefox/123.0”
and a ton of smaller UAs. These browser versions are way too old for them to be used by humans - so they’re most likely spoofed4. But again… why? Following that, I ran some statistics on the set of 1.3 million distinct IPs5, and got some interesting results. I have requests from 176 different countries, but the top 5 are:
- Brazil with 709k IPs
- Vietnam with 259k IPs
- Argentina with 54k IPs
- Ecuador with 28k IPs
- Indonesia with 20k IPs
Since I have no users in those countries on that web thingie, I know that all of that is junk traffic. I see traffic from almost 15k different ISPs - but VNPT, Telefonica Brasil, Claro NXT, V.tal, and Desktop Sigmanet are leading the list with more than a third coming from those6. So, not only is this geographically distributed, but it seems like it’s mostly residential internet connections and even mobile phone networks. Is this… a global crawling botnet that’s coded so badly, it’s almost humorous?
Earlier today, I read this article about a crawling botnet that is effectively built on top of browser extensions. I was oddly intrigued by this, especially given what I’m seeing now - and I do wonder if this is related somehow. But of course, I don’t really have a way of verifying that at the moment. But… who would waste a botnet like that on crawling something uninteresting I run?
Ultimately, this post has no satisfying conclusion. I have no clue what’s going on. It’s not a huge deal because it’s not affecting my infrastructure too badly, but I’m still annoyed and intrigued. If you have any clue what might be going on, or if you see similar patterns on something you run, do let me know. You can leave a comment under the post for this article on diaspora* or Mastodon, and more direct contact channels are listed here. If you know someone who might know more, please do share this article.
I will update this post if I learn something new.
Updates
- 2025-07-11: I had a private conversation with a security researcher who looked into a very similar incident, and while it’s hard to say that my traffic is caused by Mellowtel or something else, there’s a very high likelihood that this is, indeed, a web crawling network, most likely for LLMs. I hate this timeline.
Footnotes
-
A fate I wouldn’t wish on my worst enemy. One of the commenters there even had the audacity to claim I made everything up. I love the Orange Site; they never stop being funny. ↩
-
Including one where someone interviewed me - and then managed to credit/cite the wrong “Dennis Schubert” in the article. They probably just Googled my name and somehow.. picked the wrong Dennis to profile? After.. y’know.. talking to me, writing me LinkedIn messages… I’m honestly impressed. Probably just asked ChatGPT to write a profile about “me”. ↩
-
Yes, they follow redirects. ↩
-
And like, who uses Edge?!?! ↩
-
Shout-outs to the geoip2fast project! ↩
-
If you work for any big ISP, even from countries not listed here, reach out and I’m happy to share IPs and request logs for your ASNs. But please be prepared to verify your identity somehow. ↩